
How we cut web fuzzing FPs by 50% using Machine Learning



As much as we enjoy our work as security practitioners, no one’s giving us back the hours lost to the void of false positives.
Between the pressure to deliver actionable remediation plans, the noise many tools create, and our personal quality standards, things can get… frustrating - fast.
How do we know this?
From 3 sources:
Talking to our customers almost on a daily basis
Eating our own dog food (aka using our own product)
From our colleagues from offensive security services battle-testing Pentest-Tools.com in every engagement (and not holding back on feedback).
That’s why detection accuracy has always been our north star across every part of our product. If you’re a customer, you’ve seen this in our monthly updates, in our benchmarks, and, most importantly, in your findings.
Most recently, we focused our obsession with quality on a key capability in our web vulnerability tools: web fuzzing.
Like you, we battled the complexities of dynamic content, multilingual sites, and the endless variations of "not found."
So we reimagined web application classification, moving beyond endless, simple rules to build something smarter: our own Machine Learning classifier that can discern signal from noise - fast and at scale. You can read all about how the initiative started in the first part of this story.
This new capability led to a game-changing 50% reduction in fuzzing false positives and a whopping 92% accuracy (up from 75%).
We’re excited to share the behind-the-scenes details with you and see what it looks like when you take for a spin!
The frustrating reality: when good tools go noisy
We don’t know a single security specialist who hasn’t felt the sting of traditional web fuzzing and scanning tools. While they promise speed, the truth is often a different story.
Traditional web fuzzing and scanning tools rely on rule-based or regex-heavy classifiers. And, while these methods are fast, they’re brittle. They often mislabel pages, fail to detect dynamic content, and don’t generalize well across different web stacks or languages.
That creates several painful challenges:
Missed sensitive content (false negatives)
Too many hours wasted reviewing false positives
Time spent manually adjusting fuzzing tool filters.
These problems are bound to push anyone’s buttons. But it doesn’t have to be this way.
This is why we turned to ML to inject more intelligence and automation into the heart of our scanning pipeline.
Our answer: a smarter, more nuanced classification model
Since it’s not our style to simply complain about a problem, we focused on building a better solution – one that truly understood the nuances of web application vulnerability assessment.
First, we stepped back and looked at the core of the issue:
How do we actually understand what a web server is throwing back at us during a fuzzing session?
Instead of relying on blunt, easily fooled rules, we reimagined the problem as a classification Machine Learning task.
We trained an ML model to differentiate between various types of responses, each with its own implication during a security assessment:
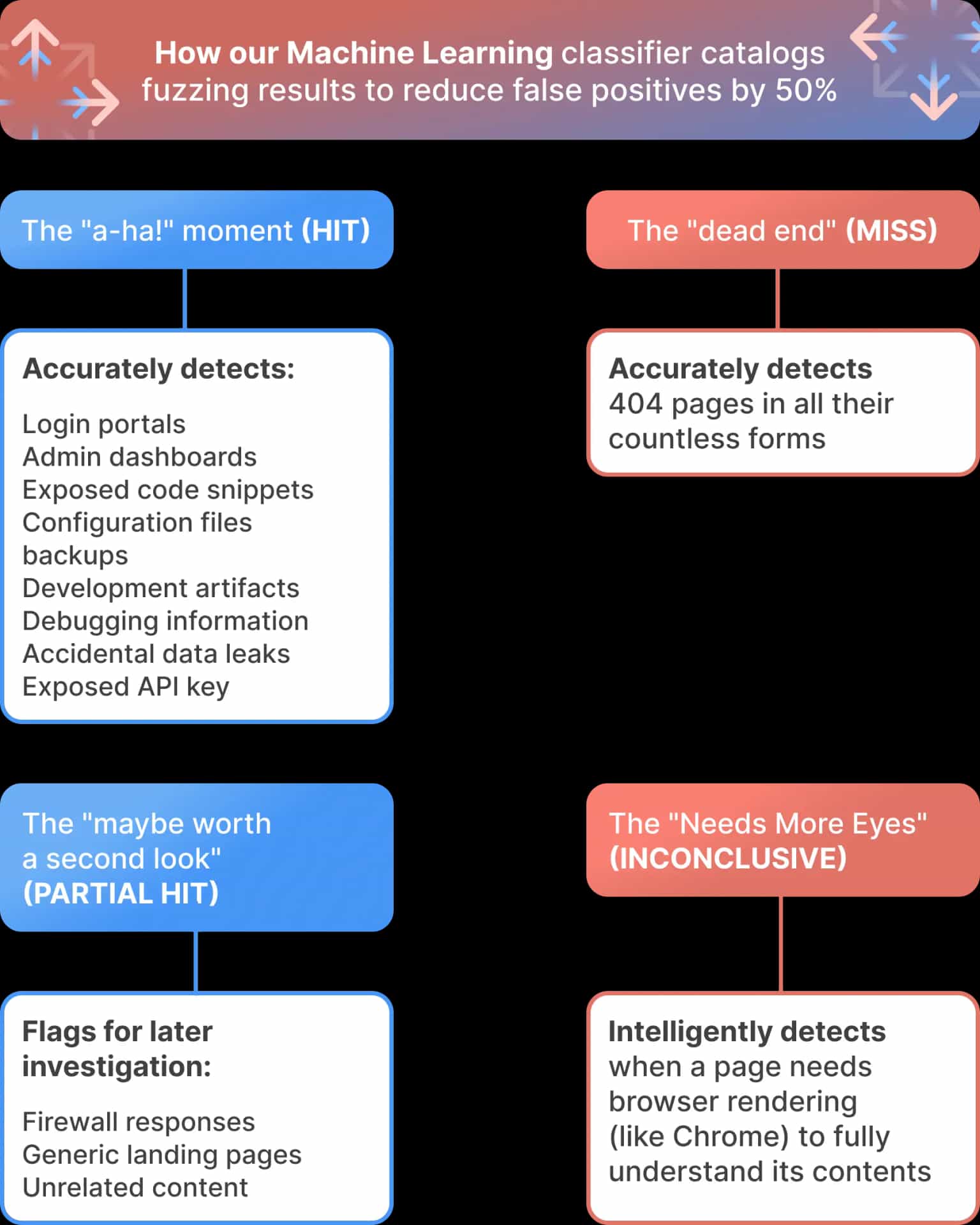
The "a-ha!" moment (HIT)
This is the gold! Content that screams potential value or directly matches what we were looking for. Imagine the satisfaction of instantly pinpointing login portals, admin dashboards, exposed code snippets, configuration files, backups, development artifacts, debugging information, accidental data leaks, or even those oh-so-critical exposed API keys. Our model is trained to recognize these "wins" with high precision, even considering redirects to give you the full picture.
The "dead end" (MISS)
Those are the 404 pages in all their countless forms. Whether it's a standard not found page or a creatively disguised "resource not here" message, our model quickly identifies these and helps you move on.
The "maybe worth a second look" (PARTIAL HIT)
These are the tricky ones – responses that aren't immediately a hit or a miss, but could still hold clues. Think of firewall responses, generic landing pages, or unrelated content that could become relevant in a broader attack scenario. Our model flags these for potential later investigation, preventing you from completely overlooking something potentially valuable.
The "Needs More Eyes" (INCONCLUSIVE)
The modern web is dynamic. Lots of content loads with JavaScript. Our model is smart enough to recognize when a page needs to be rendered with a browser like Chrome to truly understand its content. This crucial insight prevents misclassification and ensures you don't dismiss something important simply because its initial HTML is misleading.
What this means for you: less grind, more impact
So, we built this intelligent classifier. But what does that actually mean for your day-to-day work?
It boils down to this: more automation where it counts, leading to tangible benefits across the board.
Smarter automation powered by Machine Learning
Consultants that use Pentest-Tools.com for web app assessment reclaim significant chunks of their time. By letting our ML model handle the initial, often tedious, result classification, you can drastically reduce the hours spent reviewing raw scan data and jump straight to crafting insightful, client-ready reports - the ones that prove their expertize and experience.
Our Machine Learning classifier also helps MSPs/MSSP deliver consistently high-quality results across all clients without their team getting bogged down in manual triage. With greater efficiency comes the ability to handle more engagements - without sacrificing accuracy.
For internal security teams, our model makes navigating the complexities of large infrastructures becomes less daunting. While initial vulnerability triage works efficiently in the background - across thousands of assets - these time-pressed teams can focus on in-depth analysis and remediation of the truly critical issues that expose their organizations.
Real numbers, real impact on risk
This isn't just theoretical. We put our ML classifier to the test in real-world scenarios, comparing its performance against our previous, non-ML methods.
The results speak for themselves:
We saw a 50% reduction in the volume of fuzzing results from our Website Vulnerability Scanner. That's half the noise you have to comb through!
Our URL Fuzzer also experienced a significant 20% decrease in irrelevant findings.
Beyond just volume, the accuracy skyrocketed.
Our model boosted the F1-score from 75% (our previous best) to an impressive 92%, meaning fewer false positives and a much higher precision in identifying actual vulnerabilities.
This translates directly into tangible advantages for you and your team:
Use this data to demonstrate clear, measurable improvements in your organization's risk posture and to prove the value of your assessments.
Focus your team's energy on addressing actual vulnerabilities, not chasing down ghost exposures.
Build stronger trust with stakeholders by providing them with cleaner, more accurate, and ultimately more reliable data about web app security risks.
Seamless integration, immediate value
This powerful HTML classifier isn't some standalone tool you need to wrestle with. It's baked right into Pentest-Tools.com, working seamlessly through the Website Vulnerability Scanner and URL Fuzzer you already know. We are also gradually adding it into more of our pentesting tools, where error or 404 page detection is crucial.
There's no complicated setup – just smarter, more accurate scanning from the moment you run your next assessment.
Under the hood: how we made it so smart
Building a truly intelligent system isn't magic; it's meticulous engineering and a healthy dose of data science obsession.
Here's a peek at how we crafted our ML-powered HTML classifier to achieve that 92% accuracy.
Cleaning up the mess: our preprocessing power
Think of raw HTML as a messy kitchen after a cooking frenzy. It's full of tags, irrelevant bits, and inconsistencies.
To feed our ML model the good stuff, we built a preprocessing pipeline that meticulously transforms this chaos into order.
This pipeline works by:
Extracting and normalizing tags: we pull out the essential HTML tags and ensure they're presented in a consistent format.
Removing the unnecessary: we intelligently filter out irrelevant elements that would only confuse the ML model.
Handling the curveballs: our preprocessing is designed to carefully handle edge cases and unexpected structures, ensuring a smooth and consistent input for the classifier, no matter how quirky the original HTML.
Keeping things private: we took extra care to anonymize any references to specific domains or resources during this process.
Ensuring a fair learning environment: to minimize bias and ensure our model learns generalizable patterns, we meticulously curated our training data, using clever techniques (heuristics) to remove duplicates and ensure a diverse range of examples. We wanted our model to learn from a balanced and representative dataset.
The result of this heavy-duty preprocessing?
Not only does it dramatically speed up the training and the real-time analysis (inference), but it also guides our model away from latching onto misleading patterns. It focuses on the core semantic meaning of the HTML.
The brains of the operation: our ML models
For the core intelligence, we didn't just pick any off-the-shelf solution.
We fine-tuned powerful LLaMA models (specifically versions 3.1 and 3.2, with 8 billion and 3 billion parameters respectively).
To make these large language models efficient for our needs, we used clever techniques like parameter-efficient LoRA training combined with quantization.
Think of it as giving a brilliant but resource-intensive expert the specific training they need for the task, while also making them incredibly efficient in their work.
This approach allows our model to understand the nuances of security-relevant content across various languages and a multitude of web formats without requiring massive computational power.
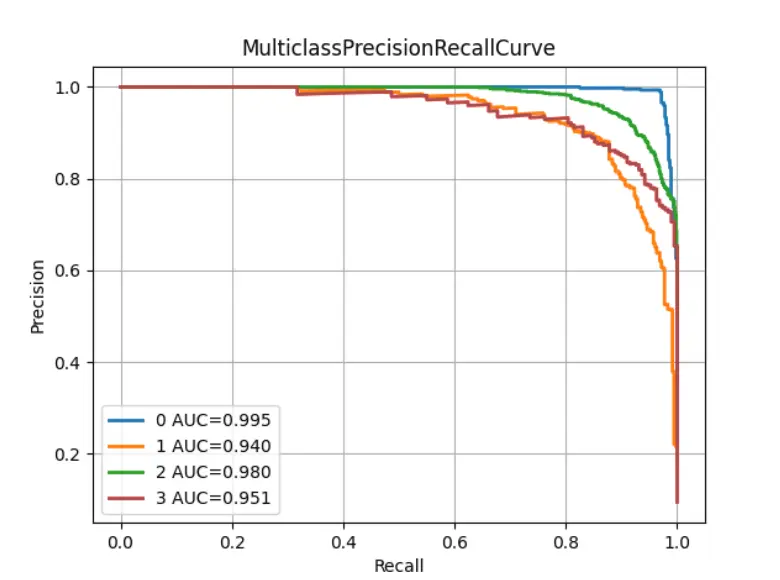
The proof in the pudding: our performance metrics
We're not just making claims; we have the numbers to back them up.
As we mentioned earlier, our classifier achieved a 92% weighted F1 score when compared to the 75% of our previous methods in the Website Scanner.

This allows our scanners to use tools like a headless Chrome Browser for a more accurate classification, a feature that was almost impossible with purely static analysis.
Seeing beyond the code: qualitative insights
While the numbers are compelling, our analysis went deeper. We discovered edge cases that traditional, rule-based systems could only dream of handling.
Speaking your language (literally)
One of the most impressive capabilities of our ML model is its multilingual understanding. It can recognize patterns indicative of a "Not Found" page in numerous languages – something that would require an ever-growing and complex set of specific rules in a traditional system.
Here are just a few examples our model correctly identified in the wild (and hadn't even seen during its training!):
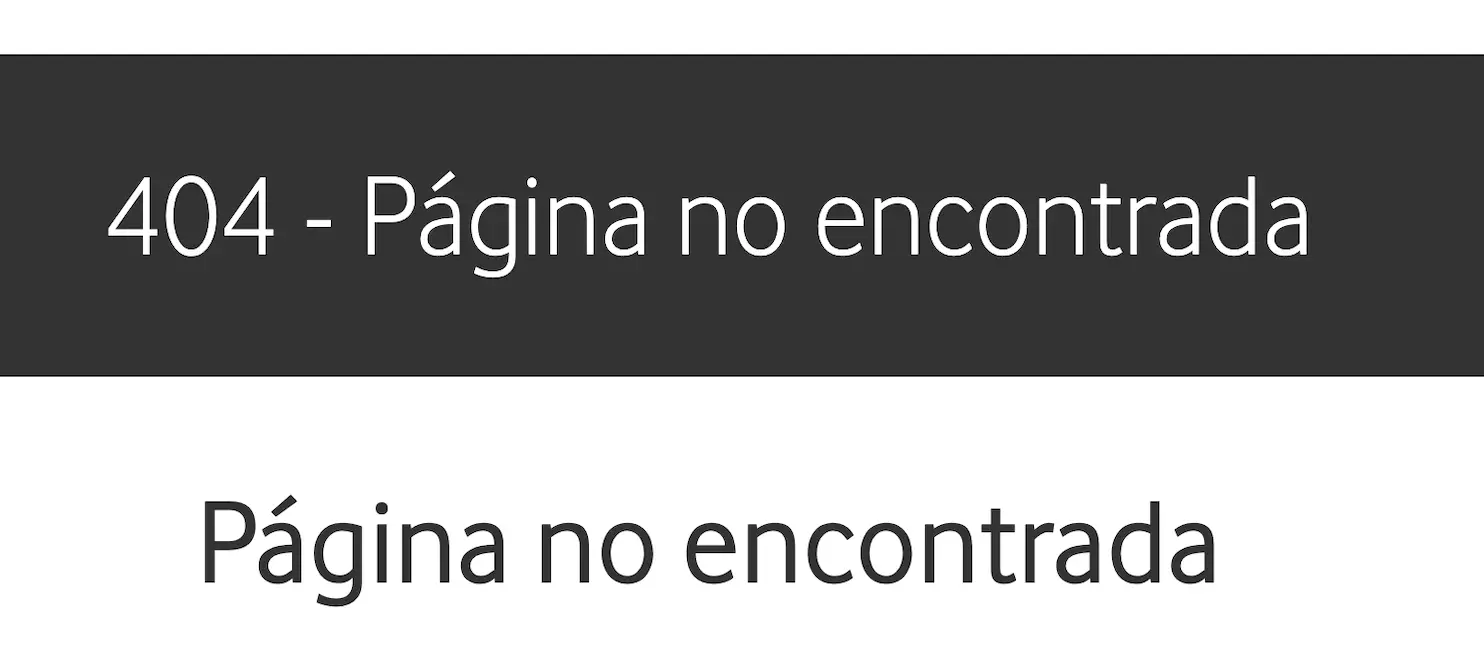
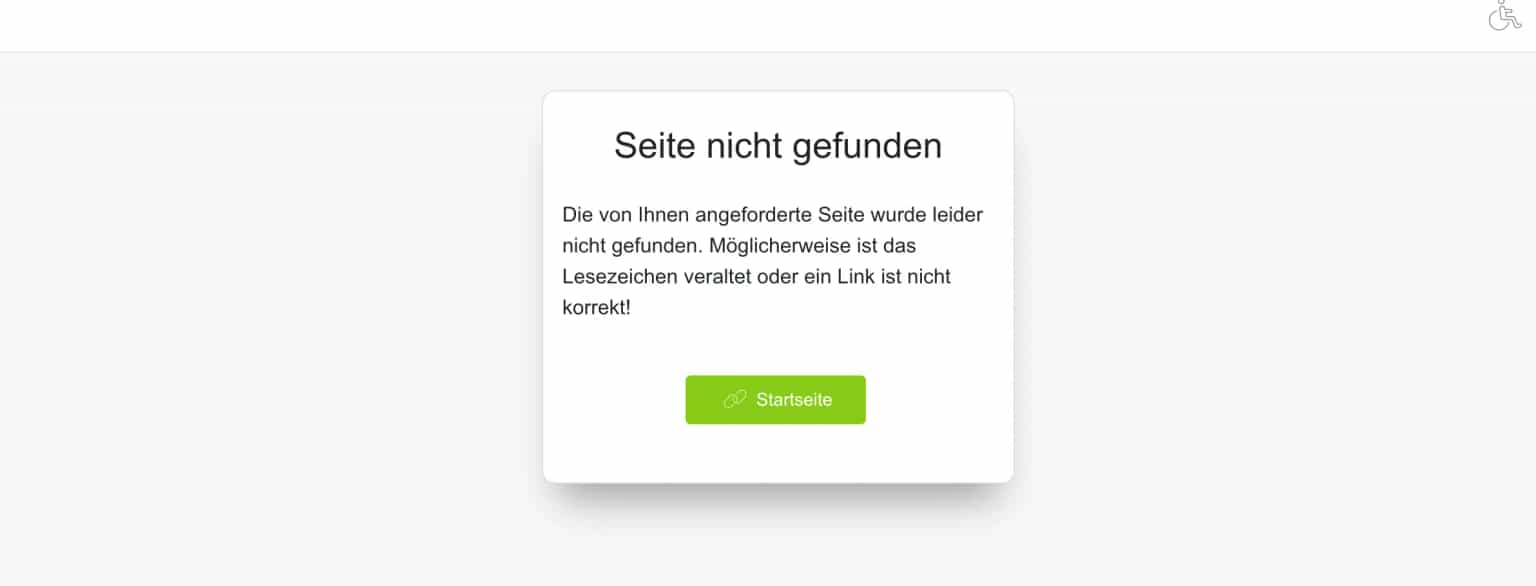




This ability to understand context beyond specific keywords in English is a significant leap in handling the diverse landscape of the modern web.
Decoding the "soft" signals
"Not Found" doesn't always come in a standard 404 package. Sometimes it's a "200 OK" with a JSON body saying "error," or a blank page with an image.
Our model has learned to recognize a very large number of these subtle cues, the "soft 404s" that often slip past traditional scanners. Here is a small sample of real-life examples we discovered while building this ML classifier:
500 - Internal Error
response_code=500, response_content='{"status":false,"error":"Internal Server Error","message":"This page dosent exist!"}No content, just an image
… <img alt="File has been removed" src="404-remove.png"/> …400 - Error Code
response_code=400, response_content='"No such file"'300 - Multiple Choices
<html><head><title>300 Multiple Choices</title></head><body><h1>Multiple Choices</h1>The document name you requested (<code>/.eslintrc</code>) could not be found on this server.However, we found documents with names similar to the one you requested.Invalid file name
response_code=200, response_content='file=api/v1/seriesInvalid filename!Oops
response_code=200, response_content='Ooops.'The famous “I’m a teapot” response
We also found a very nice easter egg: the April Fools' jokes of 1998 and 2014.
This ability to understand the intent behind the response, regardless of the status code and phrasing, drastically improves the accuracy of our fuzzing efforts.
The verdict: smarter scanning for a saner security workflow
Through this deep dive, we've shared not just what we achieved, but also a glimpse into how we tackled the persistent problem of noisy fuzzing results.
Along the way, we learned some valuable lessons that we believe are worth sharing.
The power of proof
We'll admit, even we were a little skeptical about the real-world impact of applying Machine Learning to this challenge. Seeing a tangible 50% reduction in false positives in our Website Scanner wasn't just a metric – it was a powerful validation.
It proved that with the right approach, significant, quantifiable improvements in detection accuracy are not just possible, but achievable.
Leveraging existing brilliance
Reinventing the wheel rarely makes sense.
Fine-tuning existing, powerful models like LLaMA gave us a significant head start, especially when it came to understanding the nuances of multiple languages and providing context based on security knowledge right out of the box. This saved us considerable time and resources compared to building something entirely from scratch.
The modern web demands more
We also gained a deeper appreciation for the complexities of modern web applications. The rise of JavaScript-heavy sites and Single-Page Applications (SPAs) means that static analysis alone often falls short. This realization led to the crucial "INCONCLUSIVE" classification, guiding our scanners to employ browser-based rendering when necessary for accurate analysis – a capability we believe is essential for truly effective fuzzing today.
Why Machine Learning (and not AI)
While security automation has moved beyond a nice-to-have to become a fundamental necessity, we believe in handling it with the security mindset’s sharpest weapon: our critical thinking.
Since you’re probably wondering why we didn’t talk about AI so far, let’s address this.
Just like you, we’re also saturated with often-overhyped promises of general AI. And so, we intentionally avoid this term because AI can often mask a lack of real substance - and that’s not us.
We're not chasing hype; we're building solutions that deliver real accuracy.
Our approach to automation at Pentest-Tools.com is grounded in genuine engineering.
We prefer to focus on rigorously trained Machine Learning models that deliver demonstrable results - because automation without precision creates more work, not less.
This journey to 92% accuracy isn't the finish line, but a significant milestone in our relentless pursuit of higher quality and more actionable security insights for those on the front lines.
Ready to experience the difference that smarter web vulnerability scanning can make?
Take Pentest-Tools.com for a spin and see our ML classifier in action!
We think you'll like what you find (and what you don't!).









